
AI Agent Architecture Diagram: The Two-Layer Model That Prevents Costly Errors

A reliable AI agent, especially in real-world business workflows, works best when it is built on two or more distinct layers that handle different types of decisions in fundamentally different ways. Understanding that structure before you build will help your agents perform reliably in real conditions and drastically reduce unpredictable errors.
The ai agent architecture diagram below maps the split. One layer handles rules. The other handles reasoning. Confusing which decisions belong where is one of the most common reasons AI agents make errors in production, and it has nothing to do with which LLM model or vendor you chose.
This article walks through one of the simpler AI agent architectures, shows what belongs in each layer, and explains why getting that division right matters more than prompt engineering.
What Is AI Agent Architecture?
AI agent architecture is the structural design of an autonomous AI system — the decisions about which logic runs as deterministic code versus AI inference, how memory is organized, and how the agent connects to external tools and systems. It is what determines whether an agent behaves reliably under real business conditions or only in controlled tests.
The choices made at the architecture level — not the model selected, not the quality of the prompts — are what determine how an agent performs when it is touching your CRM, your client communications, or your financial records. This post maps the core of that structure: the split between rules and reasoning.
Why AI Agents Make Mistakes (It's Not What You Think)
People blame the AI model when an agent misbehaves — but usually the blame belongs to the system design, not the model.
A recent 13-hour cloud outage was widely reported as being "caused by the provider's own AI tools," but the company's post-mortem made it clear the real issue was misconfigured permissions and access control in the surrounding system — not a failure of the underlying model itself.
AI models are probabilistic. They generate responses by calculating the most likely correct answer based on context. That works well for ambiguous, judgment-heavy tasks where context matters and no single answer is always right.
It works poorly when the correct answer is always the same.
If your CEO only takes meetings on Monday, Tuesday, and Wednesday, that isn't a judgment call. It's a rule. When you ask a probabilistic system to "reason" about your CEO's availability, you're inviting variability where none should exist. Even with excellent prompting, an AI might get it right 99% of the time. The 1% is when it schedules a Thursday call and you find out the hard way.
Fixing the architecture can't be accomplished with merely a better prompt. You need to decide what never gets handed to the AI model in the first place — and take control of what the model gets to reason over.
The Two-Layer AI Agent Architecture Diagram
A well-built agent is not one giant block of AI reasoning. It should have two or more distinct layers working together.
The deterministic layer handles rules where A always equals B. This is traditional programming. No AI model should be involved directly. The logic runs the same way every single time.
The AI reasoning layer handles everything else — where inputs are ambiguous, context changes the right answer, or natural language needs to be interpreted. This is where AI adds real value.
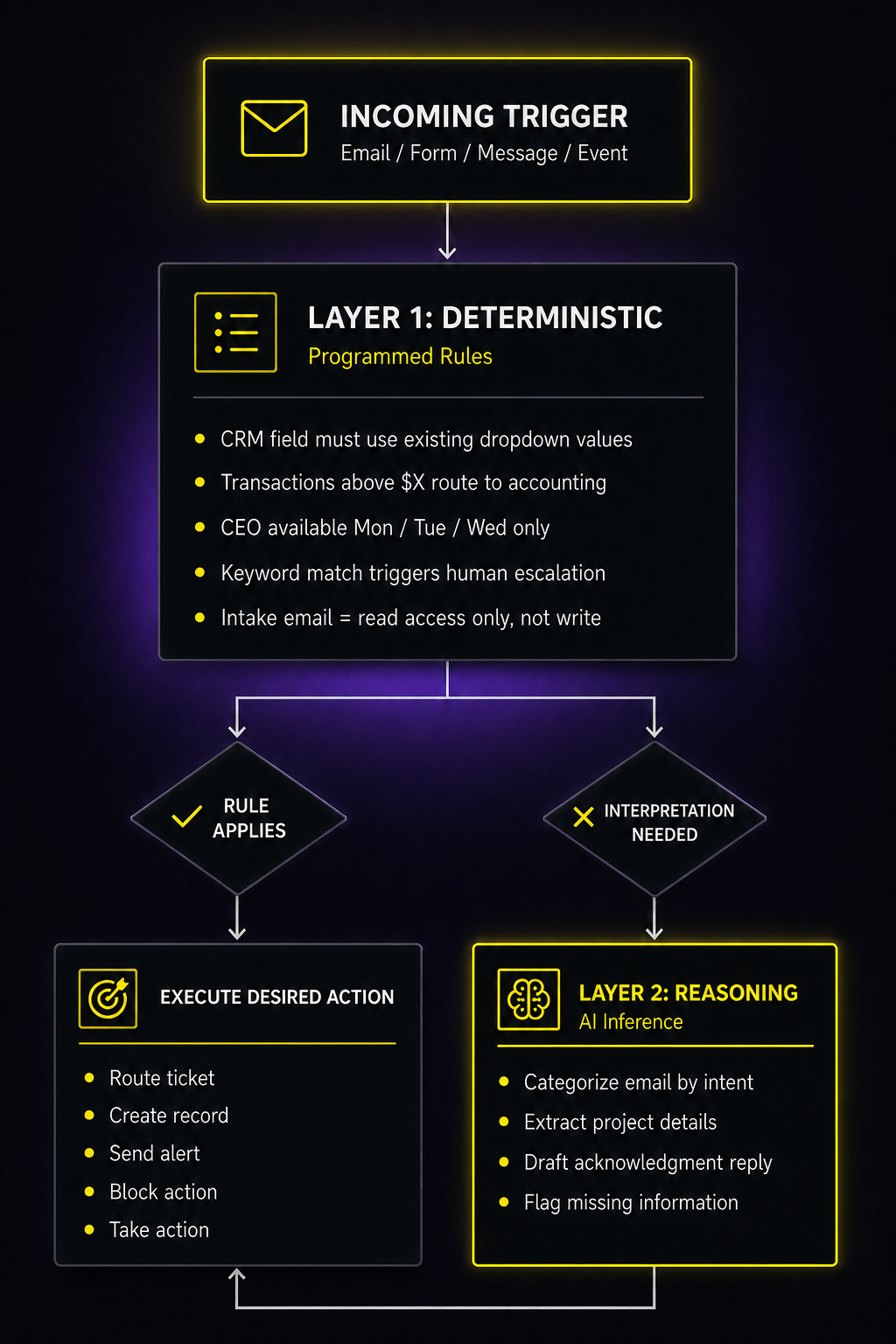
| Property | Layer 1: Deterministic | Layer 2: Reasoning |
|---|---|---|
| Governed by | Code | AI model |
| Consistency | Identical every time | Varies by context |
| Best for | Rules with one right answer | Inputs requiring interpretation |
A common mistake when building AI agents — especially with turnkey tools — is routing everything through the reasoning layer because it's easier to set up. You write one prompt, the agent handles everything, and it works most of the time. "Most of the time" is fine for low-stakes workflows. It's not fine when the agent is touching your CRM, your client communications, or your financial records.
A Simplified View of a Deeper Stack
This two-layer model is a simplification on purpose. In real production systems, the rules layer and the reasoning layer usually sit inside a richer stack that also includes a dedicated memory layer, an orchestration layer, and a governance and observability layer.
The memory layer handles what the agent remembers across runs — from operational state to durable knowledge and institutional records — so the model is never guessing from a blank slate. The orchestration layer coordinates triggers, scheduling, tool access, and routing so the right work reaches the right agent logic at the right time. The governance layer adds human-in-the-loop approvals, access controls, and audit trails so an agent can act inside real business systems without becoming a black box.
For the rest of this article, we focus on the decision core: separating deterministic rules from AI reasoning. In practice, you will get the best results when that core is supported by explicit memory, orchestration, and governance — instead of being treated as "just a prompt" in front of a model.
What Should Always Be Programmed, Not Reasoned
Before you start building your AI agent, it's worth cataloging every decision in your target workflow and asking: "Is there ever a case where the right answer is different?"
If the answer is no, that decision belongs in the deterministic layer.
Examples that almost always belong in the deterministic layer:
- Financial routing rules. Transactions above a defined threshold always go to accounting for review. No exceptions, no interpretation.
- Scheduling constraints. Specific team members are only available on specific days. That's a rule, not a context call.
- CRM field values. If a field uses a dropdown with fixed options, the agent should write only from that list — never create a new option. If it reasons through the field value, you'll end up with five variations of the same status clogging your pipeline (e.g., "complete," "done," "closed").
- Escalation triggers. If a message contains specific keywords, it goes to a human. Always.
- Read-write access by context. An agent reviewing an intake email doesn't need write access to your billing system. Controlling access at the code level removes entire categories of risk. Don't give an AI agent write access to a system when it doesn't need it.
- Model selection by case sensitivity. If certain message types qualify as sensitive, the routing to a more capable model should be a programmed rule — not a decision the agent makes for itself. The code classifies the case and routes accordingly. If the stakes are high, automatically call a more capable model. If not, use a budget model.
These decisions are deterministic because the correct answer doesn't change based on context. There's no reason to have an AI reason through things that don't need to be reasoned through.
Where AI Reasoning Actually Matters
Once you've locked down the deterministic layer, the reasoning layer can do what it's genuinely good at.
Reading and categorizing incoming emails, for example. The sender might be an existing client, a new prospect, a vendor, or someone responding to an old thread. The language varies, the context changes, and the right categorization requires actual interpretation. That's a job for AI.
Drafting acknowledgment replies falls in the same category. The tone and content should vary depending on what the sender wrote. A rigid template handles this poorly. AI handles it well.
Other strong use cases for AI reasoning in a business agent:
- Summarizing long email threads before routing them to a team member
- Identifying missing information in a client intake submission and requesting it
- Flagging messages that need human review before any action is taken
- Parsing unstructured inputs into structured data fields
The reasoning layer handles the work that changes based on context. The deterministic layer handles everything where context is irrelevant. Together, they produce an agent that's both capable and predictable.
AI Agent Memory: Keep Stores Separate
One architectural discipline that most agent guides skip: your agent needs distinct memory stores, and conflating them creates its own category of errors. We often use three, though the exact number can vary depending on agent use case and company data structure.
Operational state is what the agent is actively tracking right now: pending actions, approval queues, counters, in-progress tasks. It's ephemeral. It should change constantly and never be treated as a knowledge store.
Durable knowledge is what the agent has learned over time: client preferences, standing operational rules, patterns worth retaining across sessions. This is curated and persistent, and it should be kept cleanly separate from moment-to-moment operational data.
Authoritative institutional records live in your CRM and project management system. These are the source of truth for client identity, history, and task status. The agent reads from them and writes back to them, but it shouldn't treat them as its own memory.
When these stores bleed into each other, error rates climb dramatically — and the errors are subtle and hard to trace. Without discrete memory stores, an in-progress task can get promoted to a standing rule, or a stale memory can override live thread context. Keeping the stores separate is an architectural decision, not a cleanup task you do later.
Turnkey vs. Custom AI Agents: Choosing the Right Tool
Turnkey agent platforms are genuinely useful in the right context. They deploy fast, require little technical knowledge, and work well for general productivity automation in low-stakes situations. If you want help drafting internal documents or answering basic customer questions, a turnkey solution probably covers it. Custom ai solutions are the right call when those platforms hit their limits.
Some notable turnkey agent solutions on the market in 2026 include:
But these solutions have real limitations when your workflows need deep, highly customized integration across multiple systems.
Connecting an agent in a tightly controlled way to your CRM, project management system, inbox, calendar, and internal Slack workspace is still something many turnkey platforms either abstract behind generic connectors or make hard to customize at a fine-grained level. When they do offer integrations, the agent logic is usually expressed primarily through prompts and high-level workflow builders — not through a hard separation between deterministic code and AI reasoning. That works well for many use cases, but it limits how precisely you can control which decisions are always rules and which are handed to the model.
For high-stakes environments — where errors have compliance implications, financial consequences, or direct client impact — that trade-off is not acceptable.
Custom ai agents built on platforms like Anthropic's Claude API (or locally hosted models like Gemma, Nemotron, or Openclaw) give you direct control over the split between the deterministic layer and the reasoning layer. You decide what gets programmed, what gets reasoned, and what level of access the agent has during each type of action. That level of control is often the difference between a tool you can trust in high-stakes workflows and one you feel compelled to constantly watch.
What This Looks Like in Practice: How We Built Vera
R Creative runs its own custom ai agent internally, and the architecture described above is exactly how we built her.
Vera monitors our inbox around the clock, every 20 minutes. When a client email arrives, she doesn't reason through whether to create a project ticket. That's deterministic. Client email arrives, ticket gets created, fields get populated, team member gets notified. Every time.
Where Vera reasons is in reading the email, categorizing the request, extracting relevant details, and drafting the acknowledgment response. Those tasks require interpretation. The rules-based outcomes that follow do not.
Before Vera ran autonomously, she ran in shadow mode. Shadow mode is not just a review queue. It's a structured approval interface with distinct response types: approve the proposed action as-is, edit the output before it runs, send it back for a full retriage with new guidance, skip the action entirely, or escalate to human handling. Each response type produces a different outcome. Each correction sharpens the agent's behavior on similar situations going forward.
Vera earned autonomous operation by clearing a consecutive approval threshold with no edits required. That bar matters. An agent that gets approved with frequent edits isn't reliable yet — it's approximating. The threshold forces an honest evaluation of whether the agent is actually ready before handing over the wheel.
That phase also exposed gaps in our own process documentation. Decisions we had never written down because they lived in someone's head surfaced the moment Vera made a reasonable choice that was simply wrong for our context.
For our team, that agent has recovered more than 40 hours per month in administrative work — with up to 80 hours during particularly busy months — with inbox triage happening multiple times per hour instead of once or twice a day. Our clients notice the difference in response times.
That system started as a problem we needed to solve internally. Now we build it for other firms.
If you want the full step-by-step process for scoping, building, and deploying an agent from scratch, the broader guide is here: How to Build an AI Agent. The architecture covered in this article is the decision framework that sits inside that process.
Who Should Build a Custom AI Agent
Not every business needs a bespoke agent. Turnkey tools serve a real market, and recognizing that matters.
Building a custom ai agent makes the most sense when:
- Admin overhead is directly competing with billable or client-facing work
- Your workflows require integration with a specific tech stack (CRM, ERP, project tracker, calendar, Slack)
- Errors have financial, legal, or compliance consequences
- You need an audit trail for agent actions
- Routing decisions are complex, multi-conditional, or context-sensitive
The industries where this comes up most are the ones where human attention is expensive and intake complexity is high. Finance and accounting firms, healthcare practices, and AEC (architecture, engineering, and construction) firms all fit that profile. Coordination overhead is high, compliance requirements are real, and every hour a professional spends on administrative work is an hour not spent on client-facing output.
If that describes your business, custom AI agent development is worth the build cost. The ROI is measurable, and it compounds over time.
Before You Build Anything
The biggest mistake in any agent engagement isn't choosing the wrong model. It's building before the process is documented.
An AI agent cannot follow a workflow that hasn't been defined. Shadow mode testing will surface the gaps, but only after the build has started. The cleaner approach is to map every trigger, decision point, routing rule, and expected output before writing a single line of code.
That's why every custom AI development project at R Creative starts with a process audit. We find out where your team's time is actually going, document what an agent would need to handle those tasks, and tell you what's worth building before we propose anything.
If you're not sure what to automate or where to start, start that conversation with us. The audit is how we figure out whether a custom build makes sense for your business — and if it does, what it should actually do.
The Short Version
AI agents make mistakes when they're asked to reason through decisions that should have been programmed.
Map your workflows. Separate the deterministic decisions from the ones that require interpretation. Program the former. Apply AI reasoning to the latter. Test in shadow mode before going live.
That architecture won't produce a perfect agent — nothing does. But it will produce one you can trust, and that's what turns AI from an experiment into infrastructure.
Explore R Creative's Custom AI Agent Services
Frequently Asked Questions
AI agent architecture is the structural design of an autonomous AI system — the decisions about which logic runs as deterministic code versus AI inference, how memory is organized across operational, durable, and institutional stores, and how the agent integrates with external tools and systems. Architecture determines whether an agent behaves reliably under real business conditions or only in controlled tests.
The two-layer model separates an agent into a deterministic layer — where rules with one correct answer are handled as traditional code — and an AI reasoning layer, where inputs are ambiguous and context changes the right outcome. The deterministic layer runs identically every time. The reasoning layer interprets, categorizes, and drafts. Keeping these layers distinct prevents the most common category of production AI errors.
Most production AI agent failures trace back to architecture decisions, not the underlying model. The most common root causes are routing rule-based decisions through the AI reasoning layer (inviting variability where none should exist), conflating memory stores so operational state pollutes durable knowledge, and granting broader system access than any single action requires. Choosing a better model does not fix these — redesigning the architecture does.
Any decision where the correct answer never changes based on context belongs in the deterministic layer: financial routing thresholds, scheduling constraints, CRM field values, escalation keyword triggers, and access control rules. Asking an AI to reason through a rule-based decision introduces variability where none should exist — it is simply the wrong tool for the job.
A production AI agent typically needs three separate memory stores: operational state for in-progress tasks and pending actions; durable knowledge for client preferences, standing rules, and patterns worth retaining across sessions; and authoritative institutional records in your CRM and project management system. Keeping these stores separate prevents in-progress tasks from being promoted to standing rules and stale context from overriding live thread data.
Turnkey agent platforms express most of their logic through prompts and high-level workflow builders. They are fast to deploy but limit how precisely you control which decisions are always rules and which are handed to the model. Custom AI agents built on direct API access give you explicit control over the deterministic layer — you decide what gets hardcoded, what gets reasoned, and what level of access the agent has during each type of action. For high-stakes environments with compliance requirements or financial consequences, the trade-off tilts toward custom.
The clearest indicator is that admin overhead is competing with billable or client-facing work — and that the work consuming time follows a repeatable process. If your workflows require tight integration with a specific tech stack, errors carry compliance or financial consequences, or routing decisions are complex and multi-conditional, a custom build is worth the investment. The prerequisite is not technical readiness — it is documented processes. An agent can only follow a workflow that exists in writing.